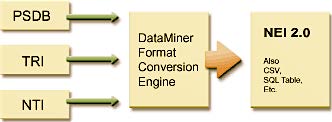
Initial data mining tests on a large database, the 3GB (text-only) Texas Point Source Database (PSDB), indicated the size of the problem. Due to existing SQL database solutions, such as Oracle and MS-SQL, searches on the PSDB database would create “views” over 1TB in size. Regulators in Texas were using large Unix workstations to enable analysis of the data. Note that making reports out of database tables does not cause this problem. It is only evident when one tries to cross reference information, which is referred to as “Mining” the data.
Few system analysts are aware that the Views in SQL stored data in a linear architecture, to facilitate cross referencing. This way, even small queries are expanded from a master reference relational structure to a linear one. Computer resources were mysteriously vanishing with our evaluations. We tried in vain to add more RAM and hard disk. After consultation with DBMS vendors, such as InterBase and Oracle, we learned that Data Mining software was being developed by independent parties to address the problem. Since we could not wait any longer for these systems we approached the problem in a unique way.
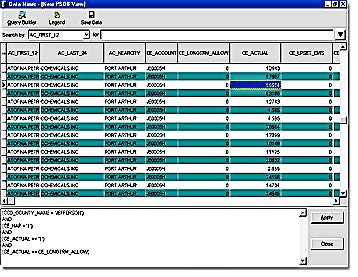
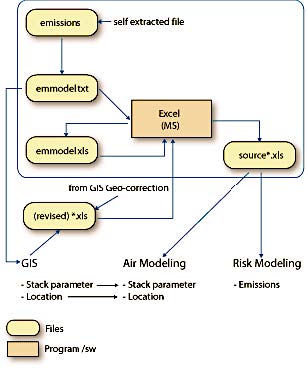
Prototype software was implemented, where users would create a Data Mining Expression using visual tools to link data and arguments. Subsequently, we would create our own SQL queries and parse the results into a linked-tree structure. Once all the data was collected, we would cross-reference the data and restore it in a new relational table structure. Using this approach, the response time to large and complex data mining expressions was fairly rapid. Memory requirements were never over the original database size.
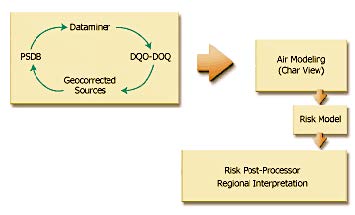
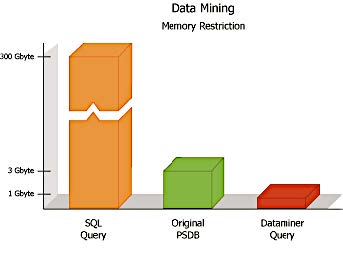
The Figure below presents actual test results with the Texas Point Source Database (PSDB). Note that our solution implementation is referred to as the “Dataminer”.